
This is a guest post by Michael Potter, edited and tailored for the Financial Services & Insurance sector by Paul Chapman, Account Technical Leader – UK Financial Services & Insurance.
IBM Storage Defender, DRS… and Why Recovery Is Starting to Feel a Lot Better
There’s been a bit of a shift in how people think about recovery lately.
It used to be pretty straightforward—have backups, test occasionally, job done.
Now it’s more about:
- what you recover
- how you recover it
- and whether you trust what you’re bringing back
Which is where tools like Storage Defender and DRS start to make a lot more sense.

Backups Are Still Important… Just Not the Whole Story
None of this is about saying backups don’t matter—they absolutely do.
But the conversation has moved on a bit.
The challenge now isn’t really:
“Do we have backups?”
It’s more:
“Are we confident we can recover something clean and usable?”
Because the way incidents play out has changed. It’s not always a clear-cut failure—you can end up with something that’s quietly spread across systems before you even notice.
So when it comes to recovery, you want more than just copies of data—you want clarity and confidence.
Storage Defender – Bringing Some Clarity
One of the things I like about IBM Storage Defender is that it tries to simplify that picture.
Instead of treating storage, backup, and detection as separate conversations, it brings them together:
- primary storage
- backup data
- threat signals
into a single view.
And that makes a real difference—because when something’s happening, the last thing you want is to be piecing together information from multiple tools.
It gives you a clearer sense of:
- what’s happening
- where the risk is
- and what your recovery options actually look like
DRS – Turning Plans Into Something Practical
The part that really stands out is DRS (Data Resiliency Service).
Because it shifts the focus away from infrastructure on its own and asks a much more useful question:
“What actually needs to come back for the business to function?”
From Individual Components to Real Applications
You still define Recovery Groups—collections of related resources like:
- VMs
- databases
- storage volumes
But then you take that a step further and define Applications.
And suddenly you’re not just recovering infrastructure—you’re recovering:
- ordering systems
- payroll
- customer services
The things people actually care about.
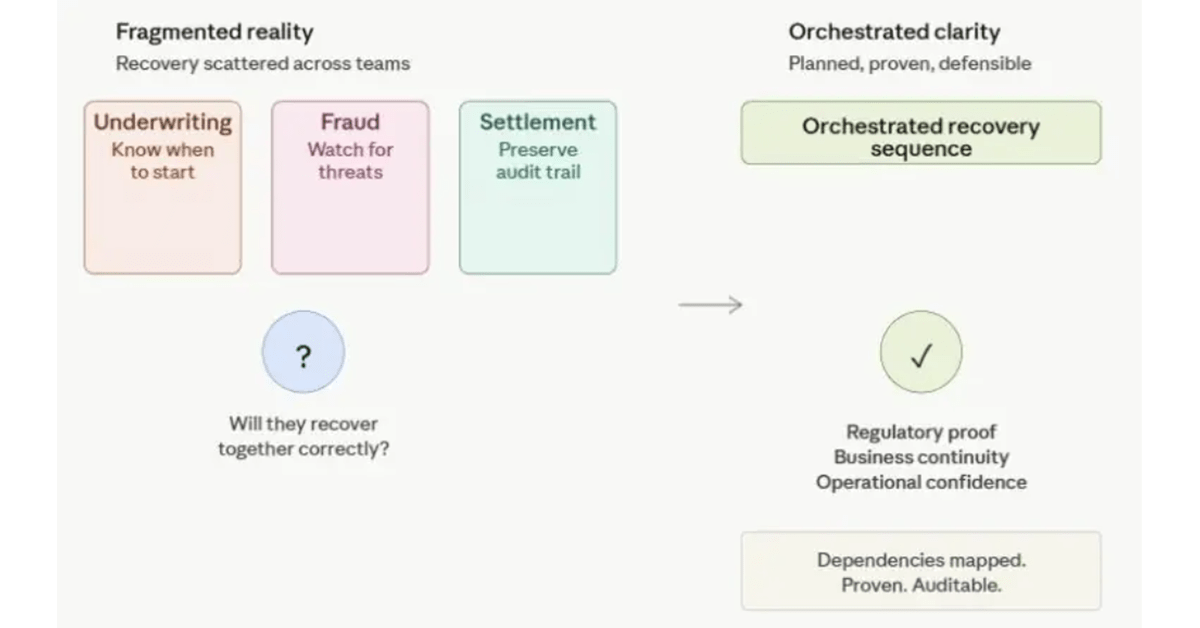
A Financial Services Example: Why Application-Level Recovery Matters
Take a major retail bank’s mortgage processing pipeline. It’s a good example of why application-level thinking changes everything.
The infrastructure stack includes:
- Customer application portal (intake)
- Affordability and credit validation services
- Document processing (OCR, automated handling)
- Underwriting systems
- Fraud detection service
- Fund settlement
Now, here’s the thing: these don’t all matter equally when you’re recovering.
With DRS, you define the recovery sequence. You might say:
- Start first: Underwriting systems and fraud detection (revenue impact + regulatory risk)
- Then: Fund settlement (regulatory compliance, audit trail integrity)
- Then: Document processing (operational efficiency)
- Last: Customer portal (you can handle portal delays longer than you can handle settlement failures)
And critically: Fraud detection must be online alongside underwriting, because you can’t process mortgages without simultaneously checking fraud flags.
This isn’t a backup admin’s job—this is a business resilience decision. And DRS makes it explicit, testable, and repeatable.
In financial services, this shift matters even more. Regulators don’t care about your infrastructure RPO/RTO—they care about whether critical services (customer-facing systems, fraud detection, settlement, audit trails) come back in the right order with the right integrity. Storage Defender + DRS helps you prove that.
A Bit More Structure, A Lot Less Guesswork
What I really like here is the ability to define:
- dependencies
- sequencing
- parallel recovery
So instead of figuring things out under pressure, you’ve already mapped:
- what needs to happen first
- what can wait
- what depends on what
It just makes the whole process feel a lot more controlled.
Knowing What’s Safe to Recover
Another area that’s improved is how we think about recovery points.
It’s no longer just:
“Pick the latest backup and go.”
There’s a bit more intelligence around:
- spotting unusual behaviour
- identifying anomalies
- highlighting safer restore points
That doesn’t replace good processes—but it definitely supports them.
And it gives you a bit more confidence when you actually need to make that call.
Clean Rooms – A Safer Way to Recover
One of the nicest additions in this space is the idea of clean room recovery.
The concept is straightforward:
Recover into an isolated environment first, validate everything, then move back into production.
It gives you the chance to:
- bring systems online safely
- check for anything unexpected
- make sure things behave as expected
before exposing production again.
Where Predatar Fits In – A Partnership Approach
If you’ve come across Predatar, this approach will feel pretty familiar.
They’ve focused on:
- isolated recovery environments
- repeatable recovery workflows
- regular testing
And here’s what’s interesting: IBM and Predatar have partnered to bring complementary benefits together.
As Matthew Smith outlined in his recent blog post, “IBM & Predatar Join Forces to Deliver Proof of Recovery”, this integration allows us to deliver something that’s been missing: proof that your recovery will actually work.
Storage Defender handles early threat detection and unified visibility across storage, backup, and threats. Predatar brings cyber recovery orchestration and isolated testing to that equation. Together, they give you both the confidence to recover and the proof that it will work.
Because recovery shouldn’t be something you only think about when there’s a problem—it should be something you’re comfortable with before you need it.

The Fundamentals Still Matter
Of course, all the key protections are still there:
- immutable backups
- air-gapped copies
- strong access controls
They’re still essential.
But now they sit alongside:
- better visibility
- smarter recovery planning
- safer recovery execution
- and proof that it works
Which together give you a much more complete picture.
Focusing on What Matters Most
One of the more practical shifts is around prioritisation.
Instead of trying to recover everything at once, it’s about:
- identifying critical services
- bringing those back first
- then expanding out
You’re not aiming for “everything immediately”—you’re aiming for what the business needs first. And that’s a much more realistic way to approach recovery.

Wrapping Things Up
What I like about Storage Defender and DRS is that they don’t overcomplicate things.
They just bring structure and visibility to areas that have often been a bit unclear:
- understanding dependencies
- choosing recovery points
- testing recovery properly
- recovering safely
It’s not about reinventing recovery—it’s about making it more reliable and predictable.
And that’s exactly what’s needed.
A Question for Your Environment
If you look at your own Financial Services operation, it’s worth asking:
- Do we know how our critical applications come back—not just our infrastructure?
- Would we feel confident choosing a recovery point today?
- Have we tested recovery in a safe, isolated way?
- Could we prove to a regulator that our recovery will work?
If those answers aren’t fully there yet, that’s fine—but it’s a good place to start.
Contact Paul
If you’re in Financial Services or Insurance and thinking about how to strengthen your recovery posture, let’s talk. Understanding your critical application dependencies and designing a resilience strategy that satisfies both business continuity and regulatory requirements is exactly what I focus on.
Get in touch or connect on LinkedIn.
For more on the IBM Storage Defender + Predatar partnership, see Matthew Smith’s blog: IBM & Predatar Join Forces to Deliver Proof of Recovery
This is a guest post by Michael Potter, edited and tailored for the Financial Services & Insurance sector by Paul Chapman, Account Technical Leader – UK Financial Services & Insurance.
Disclaimer: The postings on this site are my own and don’t necessarily represent IBM’s positions, strategies or opinions.
This article is intended for informational purposes only and does not constitute legal, regulatory or compliance advice. While every effort has been made to ensure accuracy at the time of publication, the regulatory landscape is evolving rapidly. Readers should consult qualified legal and compliance professionals for guidance specific to their organisation. References to IBM products and services are for illustrative purposes and do not constitute a contractual commitment. All regulatory citations are based on publicly available sources current as of May 2026.
Views expressed do not reflect the views of any IBM clients or partners.
Leave a Reply