

Private AI on IBM Power: How Small Language Models Are Transforming Enterprise Graph Analytics
The Enterprise AI Dilemma No One Was Solving
Enterprise technology leaders have been caught in an impossible bind. On one side, they’ve witnessed the remarkable capabilities of large language models like ChatGPT and Claude—particularly their ability to translate natural language into precise database queries. On the other side, they face the hard reality that using these cloud-based LLMs means sending potentially sensitive query patterns, schema information, and business logic to external servers.
For organizations in regulated industries—financial services managing transaction data, healthcare institutions handling patient records, government agencies protecting classified information, and enterprises safeguarding intellectual property—this data exposure isn’t just inconvenient. It’s often legally insurmountable.
But the problems don’t stop at privacy. Cloud-based LLMs come with significant operational challenges:
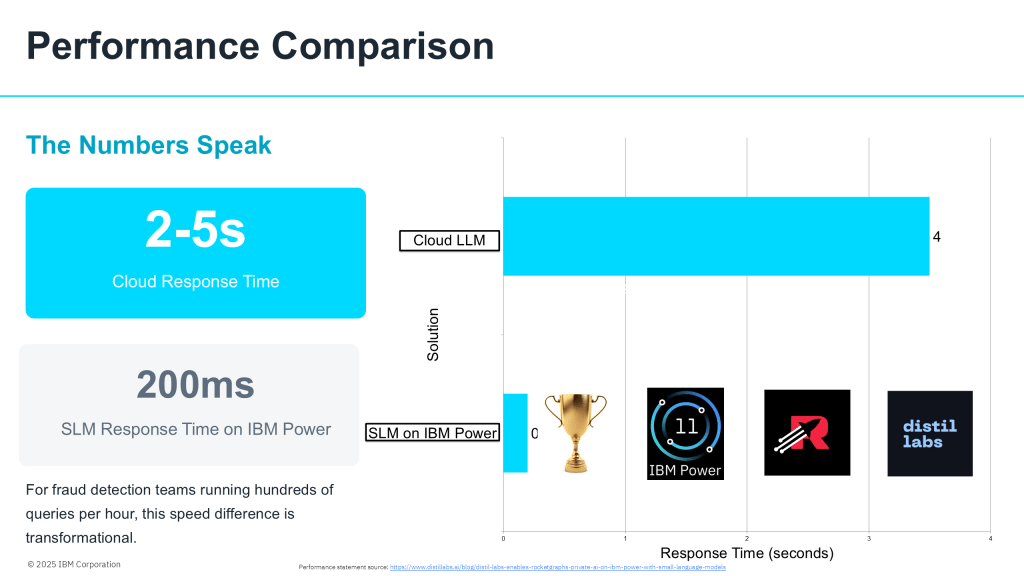
– Response times of 2-5 seconds per query, including network latency
– Financial costs that compound with query volume
– Environmental costs measured in kilowatts per inference
– API rate limiting that constrains analytical workflows
– Compliance complexity that requires extensive legal review
Organizations weren’t asking for much. They wanted AI-powered natural language querying for their graph databases. They just needed it to work within their security perimeter, at production speed, and at sustainable cost.
Until recently, they couldn’t have it.
Enter Small Language Models: Specialization Over Scale
The announcement from Rocketgraph, Distil Labs, and IBM represents a fundamentally different approach to enterprise AI—one that prioritizes specialization over generalization, efficiency over scale, and privacy over convenience.
At the heart of this solution is a Small Language Model (SLM) with just 8 billion parameters—a fraction of the size of popular cloud LLMs rumoured to exceed 1 trillion parameters. This isn’t a compromise. It’s a purposeful design choice built on a powerful insight: when you know exactly what you need to accomplish, a specialized tool outperforms a general-purpose one.
What Makes This SLM Different
The Granite 3.3 8B model has been fine-tuned specifically for one task: translating natural language queries into Rocketgraph’s variant of OpenCypher, a query language for graph databases. This specialization delivers several critical advantages:

Complete Data Sovereignty
The SLM runs entirely on your IBM Power hardware, behind your firewall, under your security policies. Your queries never leave your infrastructure. Your schema remains confidential. Your business logic stays proprietary. Compliance teams can finally sleep soundly.
10x Performance Improvement
Where cloud LLMs take 2-5 seconds to process a query (including network round-trips and API queuing), this SLM translates natural language to Cypher in under 200 milliseconds. That’s not just faster—it’s a qualitative difference that changes how analysts work. Real-time becomes truly real-time. Interactive exploration becomes genuinely interactive.
100x Energy Efficiency
The SLM consumes a few watts of power compared to the kilowatts required for large model inference in distant data centers. For organizations with sustainability commitments, this isn’t a minor detail—it’s a fundamental alignment of AI capabilities with environmental responsibility.
85% of Claude 4 Performance
Despite being orders of magnitude smaller, the specialized SLM achieves 85% of Claude 4’s performance on this specific task. This is the power of specialization: you don’t need a trillion parameters to excel at one thing.
How They Built Enterprise-Grade Privacy Into AI
The breakthrough came from Distil Labs’ expertise in knowledge distillation—the process of teaching smaller models to replicate the capabilities of larger ones for specific tasks. But the innovation goes deeper than just making models smaller.
The Training Approach: No Customer Data Required
Traditional fine-tuning often requires thousands of hand-labeled examples, which for this use case would likely contain sensitive customer information. Distil Labs took a different path:
1. Public Documentation: Started with Rocketgraph’s publicly available OpenCypher specifications
2. Synthetic Data Generation: Created 900+ schemas translated from public Neo4j datasets into Rocketgraph-compatible formats
3. Validated Examples: Generated 15,000+ training examples, all programmatically validated against the Rocketgraph platform
4. Fine-Tuning: Specialized the IBM Granite 3.3 8B model for Rocketgraph’s specific OpenCypher variant
The result? An SLM trained entirely on public and synthetic data, containing zero customer information, yet capable of understanding the nuances of Rocketgraph’s query language.
Learning Rocketgraph-Specific Patterns
The challenge wasn’t just about understanding OpenCypher generally—it was about mastering Rocketgraph’s idiomatic approach. For example, where standard Cypher might use:
```cypher
MATCH (d)-[r:EdgeType]->()
RETURN d, count(r) AS count
```Rocketgraph’s preferred pattern is:
```cypher
MATCH (d)
RETURN d, outdegree(d, EdgeType) AS count
```These distinctions matter. The SLM had to learn these Rocketgraph-specific patterns without ever seeing actual customer queries or schemas during training.
Real-World Impact: Financial Services Fraud Detection
Consider a practical scenario that illustrates why this matters. A financial institution’s fraud detection team needs to query complex relationship graphs containing:
– Customer personal information
– Transaction histories spanning years
– Account relationships and beneficial ownership structures
– Suspicious pattern indicators
– Connections to flagged entities
An analyst investigating potential fraud might ask:
> “Show me all transactions over $10,000 involving accounts opened in the last 30 days that have connections to flagged entities.”
With the SLM running on IBM Power, this natural language query is translated to precise OpenCypher in under 200 milliseconds and executed locally. The entire investigation happens within the bank’s security perimeter.
Compare this to the alternative of using cloud-based LLMs:
– Network latency: 50-100ms just for the round trip
– Query processing: 2-5 seconds in the cloud
– Data exposure: Query patterns revealing investigation focus
– Schema leakage: Structural information about the bank’s graph
– API constraints: Rate limits potentially delaying urgent investigations
– Compliance complexity: Legal review of third-party data sharing
For fraud detection where every second counts and confidentiality is paramount, the difference is transformational.
The Results
Financial institutions deploying this solution report:
– 100% data privacy: Zero information leaves their infrastructure
– Sub-second response times: Enabling real-time investigative workflows
– No API throttling: Analysts can run hundreds of queries without constraint
– Full regulatory compliance: On-premise processing eliminates third-party data sharing concerns
– Sustainable operations: Dramatically reduced energy consumption supports ESG goals
The Technical Architecture: How It All Works Together

The solution brings together three industry leaders, each contributing essential capabilities:
Rocketgraph: Graph-Native Analytics Platform
Rocketgraph provides the foundation—a graph-native analytics platform optimized for complex relationship analysis. Their variant of OpenCypher is specifically designed for the performance and scalability requirements of enterprise graph analytics.
Distil Labs: Knowledge Distillation Expertise
Distil Labs brought the specialized knowledge in model distillation that made the breakthrough possible. Their platform enabled:
– Generation of high-quality synthetic training data
– Programmatic validation of all training examples
– Fine-tuning optimization for the specific task
– Model compression techniques to maximize on-premise efficiency
For detailed technical documentation on their approach, see the Distil Labs blog
IBM Power: Enterprise-Grade Infrastructure
IBM Power provides the enterprise infrastructure that makes on-premise SLM deployment viable. The combination of Power hardware and IBM’s Granite model family creates a foundation for private AI that meets enterprise requirements for:
– Performance at scale
– Reliability and availability
– Security and isolation
– Operational manageability
Why Small Language Models Represent the Future of Enterprise AI
This collaboration demonstrates more than just a clever technical solution. It represents a blueprint for how enterprises can adopt AI without compromising on security, speed, or sustainability.
The Shift from General to Specialized
The AI industry has been dominated by the narrative of bigger models being better. But enterprise reality is different. Organizations don’t need models that can write poetry, generate images, and explain quantum physics. They need models that can excel at specific, mission-critical tasks.
Small Language Models represent this shift—from generalization to specialization, from cloud to edge, from external dependencies to internal control.
The Economics Make Sense
Consider the total cost of ownership:
Cloud LLM Approach:
– Per-query API costs accumulating over millions of queries
– Network bandwidth for data transfer
– Compliance overhead for third-party data sharing
– Potential legal exposure from data breaches
– Environmental costs from remote data center processing
On-Premise SLM Approach:
– One-time deployment cost
– Minimal ongoing operational costs
– No per-query charges
– No external data transfer
– Simplified compliance posture
– Sustainable energy footprint
For high-volume analytical workloads, the economics strongly favour specialized SLMs running on owned infrastructure.
The Performance Enables New Use Cases
When query translation happens in 200 milliseconds instead of multiple seconds, entirely new workflows become possible:
– Interactive exploration: Analysts can iterate and refine queries in real-time
– Batch processing: Thousands of queries can run without API throttling
– Embedded analytics: Natural language query capabilities can be built into user-facing applications
– Automated monitoring: Systems can generate and execute queries continuously
Speed isn’t just a nice-to-have—it’s an enabler of capabilities that weren’t previously viable.
Getting Started: Deployment Path for Rocketgraph Customers
For organizations already running Rocketgraph on IBM Power hardware, deploying the SLM is straightforward:
Requirements
– Existing IBM Power infrastructure (already in place for Rocketgraph customers)
– Current Rocketgraph installation
– No external dependencies or API keys required
– No additional hardware procurement needed
Integration
The SLM integrates directly with your current Rocketgraph installation. There’s no complex networking configuration, no firewall exceptions for external services, and no data governance reviews for third-party processors.
It’s your SLM, running on your hardware, analyzing your data, under your complete control.
Support
Full support is available from the combined Rocketgraph, Distil Labs, and IBM teams. This isn’t a proof-of-concept or research project—it’s a production-ready solution backed by enterprise support commitments.
Beyond This Use Case: The Broader Implications
While this announcement focuses on natural language to OpenCypher translation for graph analytics, the implications extend far beyond this specific application.
A Template for Private AI
This collaboration provides a template for how enterprises can deploy specialized AI:
1. Identify a specific, high-value task that requires AI capabilities
2. Partner with model distillation experts to create a specialized SLM
3. Train on public and synthetic data to avoid customer information exposure
4. Deploy on owned infrastructure to maintain data sovereignty
5. Achieve performance comparable to large models for the specific task
This pattern is repeatable across countless enterprise AI use cases.
The Environmental Argument
As AI adoption accelerates, the environmental impact of model inference becomes increasingly significant. A single large model query can consume as much energy as charging a smartphone. Multiply that across millions of queries daily, across thousands of organizations, and the aggregate impact is substantial.
Small Language Models running on efficient infrastructure offer a sustainable path forward. The 100x energy efficiency improvement isn’t just good for operational costs—it’s essential for responsible AI adoption at scale.
Regulatory Alignment
As governments worldwide implement AI regulations focused on transparency, accountability, and data protection, on-premise SLMs align naturally with these requirements. When your AI runs on your infrastructure, auditing, monitoring, and compliance become dramatically simpler.
The Technical Deep Dive: For Those Who Want Details
For technical teams considering this approach, several aspects deserve deeper examination:
Model Size and Performance Trade-offs
At 8 billion parameters, the Granite 3.3 8B model sits in the “sweet spot” for on-premise deployment:
– Small enough to run efficiently on CPUs without GPU acceleration
– Large enough to capture the complexity of natural language understanding
– Optimized specifically for the target task through fine-tuning
The 85% performance relative to Claude 4 for this task isn’t a limitation—it’s more than sufficient for production use while delivering the 10x speed and 100x efficiency improvements.
Training Data Volume Requirements
The solution required:
– 900+ schemas for diverse coverage
– 15,000+ validated query examples
– Zero customer data or sensitive information
This demonstrates that effective SLM training doesn’t require massive proprietary datasets. Careful synthetic data generation can achieve production-ready results.
Deployment Considerations
Organizations considering similar approaches should evaluate:
– Task specificity: How well-defined is your target use case?
– Data sensitivity: What are your compliance requirements?
– Query volume: How many inferences do you need daily?
– Latency requirements: How fast must responses be?
– Infrastructure availability: Do you have suitable on-premise hardware?
For high-volume, latency-sensitive, privacy-critical applications with well-defined scope, the case for specialized SLMs is compelling.
What This Means for Different Stakeholders
For CIOs and Technology Leaders
This announcement validates that you don’t have to choose between AI innovation and data governance. Specialized SLMs enable AI adoption that aligns with your security, compliance, and operational requirements.
Key considerations:
– Evaluate which AI use cases are specific enough for SLM specialization
– Assess your infrastructure’s readiness for on-premise AI deployment
– Consider the total cost of ownership versus cloud API approaches
– Factor sustainability goals into AI strategy decisions
For Data Scientists and ML Engineers
This represents an exciting shift in how AI models are deployed in production. The focus moves from maximizing general capabilities to optimizing specific tasks—a return to classical ML principles applied with modern techniques.
Opportunities:
– Explore knowledge distillation techniques for your use cases
– Investigate synthetic data generation approaches
– Learn model optimization for edge deployment
– Consider specialization as a feature, not a limitation
For Business Leaders
AI is becoming less about sending data to external services and more about deploying specialized capabilities on owned infrastructure. This changes the economics, risk profile, and strategic value of AI investments.
Strategic implications:
– AI capabilities become proprietary assets, not commodity services
– Competitive advantage comes from specialized deployment, not just access
– Regulatory risk decreases with on-premise processing
– Sustainability commitments align with AI adoption
Looking Forward: The Evolution of Enterprise AI
This collaboration between Rocketgraph, Distil Labs, and IBM points toward several emerging trends:
1. The Rise of Specialized Models
We’ll see increasing deployment of task-specific SLMs that outperform general-purpose LLMs for targeted applications. The “one model to rule them all” approach gives way to specialized tools optimized for particular domains.
2. Edge AI Becoming Central
As models become more efficient, edge deployment becomes not just viable but preferred. Data stays where it’s created, processing happens where it’s needed, and latency drops to near-zero.
3. Sustainable AI Practices
Energy efficiency evolves from a nice-to-have to a requirement. Organizations will increasingly evaluate AI solutions on performance per watt, not just absolute performance.
4. Privacy-First Architecture
Rather than retrofitting privacy controls onto cloud services, solutions will be designed from the ground up for data sovereignty. On-premise processing becomes the default, not the exception.
5. Hybrid Intelligence Strategies
Organizations will develop portfolios of AI capabilities—general-purpose cloud LLMs for broad tasks, specialized SLMs for mission-critical applications, and classical ML for well-understood problems. The right tool for each job.
Key Takeaways
1. Small Language Models can match large model performance for specific tasks while being orders of magnitude more efficient
2. Data sovereignty is achievable without sacrificing AI capabilities through on-premise SLM deployment
3. Speed improvements of 10x enable entirely new workflows and use cases in enterprise analytics
4. Energy efficiency of 100x makes AI adoption compatible with sustainability goals
5. Enterprise-grade privacy is possible when models run on your infrastructure, behind your firewall
6. Specialized beats general when you know exactly what you need to accomplish
7. The partnership model works: Bringing together graph analytics (Rocketgraph), model distillation expertise (Distil Labs), and enterprise infrastructure (IBM) creates solutions no single vendor could deliver
Resources and Further Reading
Original Announcement:
Distil Labs Blog: Enabling Rocketgraph’s Private AI on IBM Power
Technical Documentation: Distil Labs Documentation
Company Resources:
– Rocketgraph – Graph-native analytics platform
– Distil Labs – Knowledge distillation and SLM deployment
– IBM Power – Enterprise infrastructure
Contact:
For organizations interested in exploring SLM deployment for graph analytics, reach out to the Rocketgraph, Distil Labs, and IBM teams for consultation on your specific use case.
Related Content
– Video Presentation: Watch the detailed explanation on YouTube
– Slide Deck: Download the presentation
– Case Studies: Contact for industry-specific implementation examples
Comments and Discussion
Have questions about deploying Small Language Models in your organization? Considering private AI for regulated industries? Share your thoughts and experiences in the comments below.
For technical questions or implementation discussions, the combined teams at Rocketgraph, Distil Labs, and IBM are available to help evaluate your specific use case.
Disclaimer: This blog post is based on publicly available information from Distil Labs, Rocketgraph, and IBM. The author is an IBM employee sharing industry news and analysis. For official product information and specifications, please refer to the respective company websites and documentation.
Leave a Reply